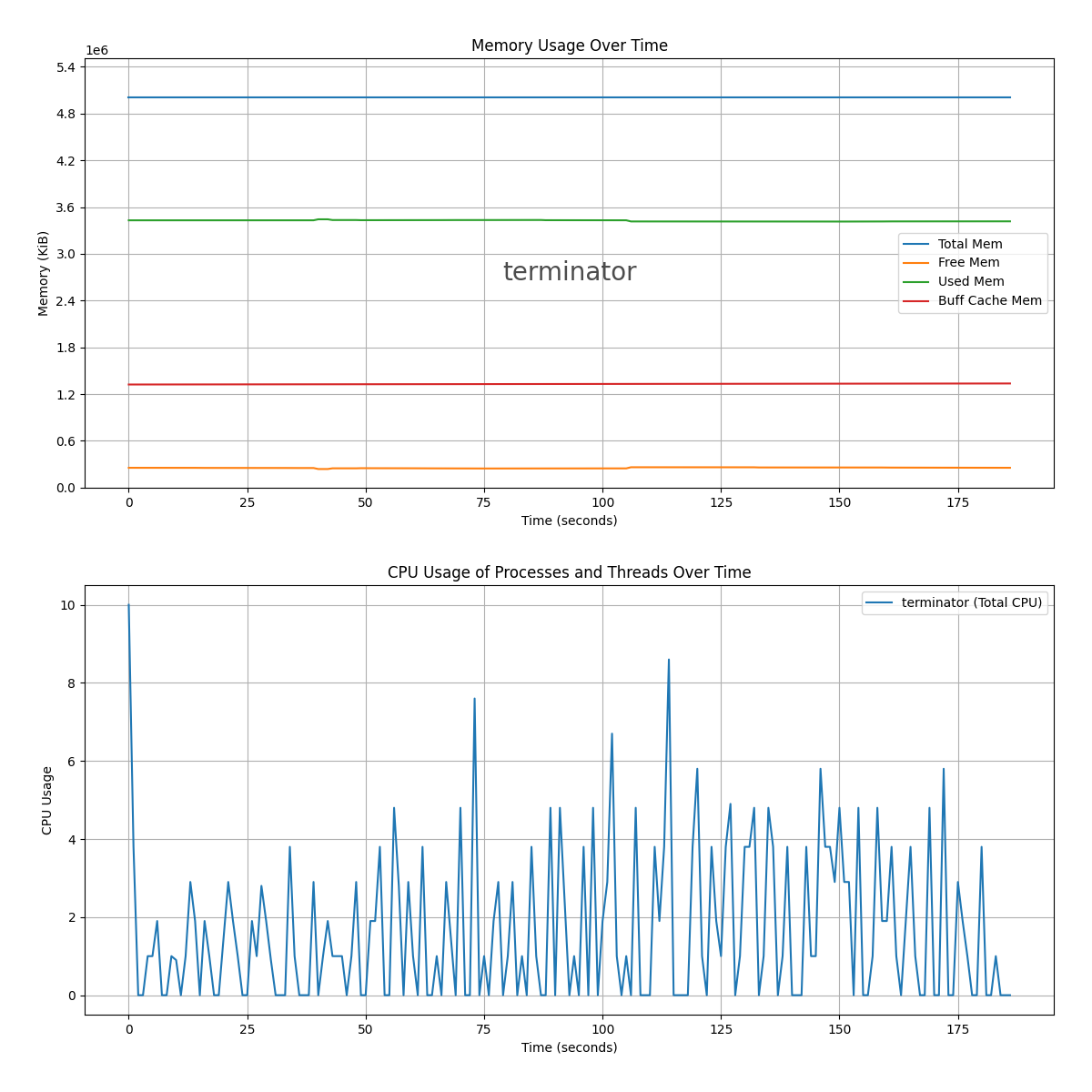
1.7 训练一个神经网络
对于训练神经网络,有两个步骤,即前向传递和误差反向传播。
1.7.1 前向传播和反向传播
在前向传递中,输入被馈送到模型并与权重向量相乘,并为每一层添加偏差以计算模型的输出。密集层或全连接层第l层的输入![]() 、 激活函数
、 激活函数![]() 和输出
和输出![]() 表示如下:
表示如下:
 (1.57)
(1.57)
其中N表示第l层的神经元数量,![]() 是第l层任务需要学习的权重,σ()是激活函数
是第l层任务需要学习的权重,σ()是激活函数
反向传播如下所述。考虑一个样本,其输入![]() 和预期输出
和预期输出![]() 和实际输出
和实际输出![]() ,因此一个样本的误差为
,因此一个样本的误差为  ,其中
,其中![]() 是权重
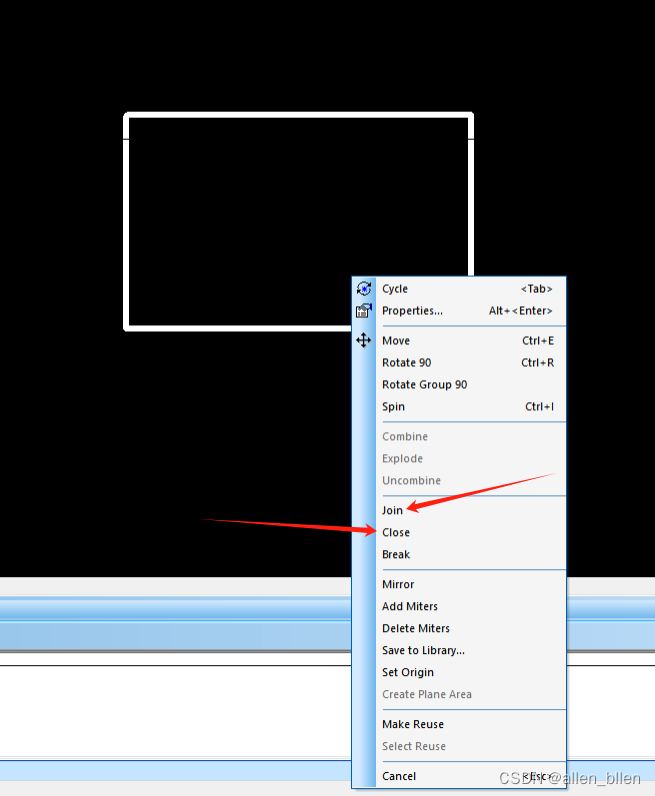
是权重![]() 的函数。使用梯度下降算法更新权重以最小化误差,可以表示如下:
的函数。使用梯度下降算法更新权重以最小化误差,可以表示如下:
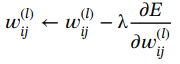 (1.58)
(1.58)
在式(1.58),![]() 可计算如下:
可计算如下:
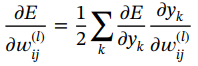 (1.59)
(1.59)
其中, 。
。
由于![]() 是
是![]() 的函数,因此可以推导出
的函数,因此可以推导出
 (1.60)
(1.60)
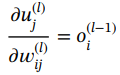 (1.61)
(1.61)
这是在前馈步骤中计算的。
因此,把它们放在一起给了我们:
 (1.62)
(1.62)
神经网络训练过程中的一些重要方面如下:
1.学习率:每次权重更新都由参数 λ 控制,称为学习率参数。如果学习率太小,那么可能会导致学习速度非常慢,很容易被困在局部最小值中,并且可以持续运行多次迭代。另一方面,如果学习率很大,那么它可能会越过最小值,可能无法收敛,并可能发散。因此,根据架构、数据集、传递函数等选择良好的学习率非常重要。图1.18说明了选择小学习率和大学习率对梯度下降的影响。
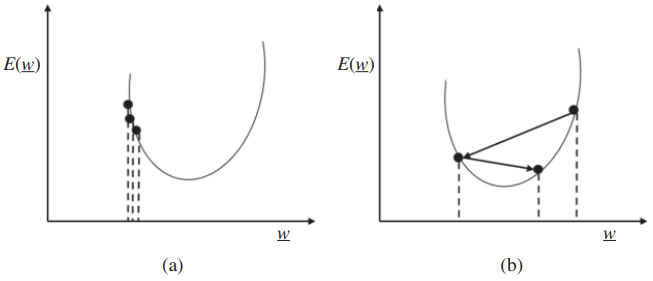
图1.18 (a)学习率小和(b)学习率大时梯度下降的图示。
2. 权重初始化:在初始化过程中随机化权重很重要;否则,权重的对称性会阻止网络学习。通常,使用小的随机值,这在层中的神经元数量增长时非常重要,因为加权和可能会使优化函数饱和。
3. 过拟合和欠拟合:在机器学习中,目标不仅是最小化样本内数据(即可用或可见的数据)的成本函数,而且还要对样本外数据(即训练期间不可用或不可见的数据)进行泛化。在训练过程中,可用的数据集分为训练集、验证集和测试集。训练数据集用于训练模型,验证数据集用于设置模型的超参数,测试数据集用于估计样本外或泛化精度。
当训练数据的性能较差时,可以将其视为欠拟合,通常是由于学习率选择不当或神经网络维度不足。此错误称为“偏差”。图1.19的左列说明了欠拟合问题。当训练数据的性能良好(即近似精度好),但测试或验证数据性能差(即泛化精度差)时,就会出现过拟合问题。这种现象也称为“方差”,如图1.19的右栏所示。如果训练集大小不足或模型复杂度对于数据来说太高,则模型可以很好地记住或近似训练数据,但不能很好地泛化测试数据,即过度拟合。训练机器学习模型的目的是找到一个如图 1.19 中间列所示的模型,其中训练误差(偏差)和泛化误差(方差)最小化。通常,训练会找到一个模型,以便在偏差和方差之间实现平衡,通常被称为“偏差-方差”权衡。在深度学习的情况下,“偏差-方差”权衡不适用,因为有单独的机制来减少偏差和方差,因此权衡不容易适用。
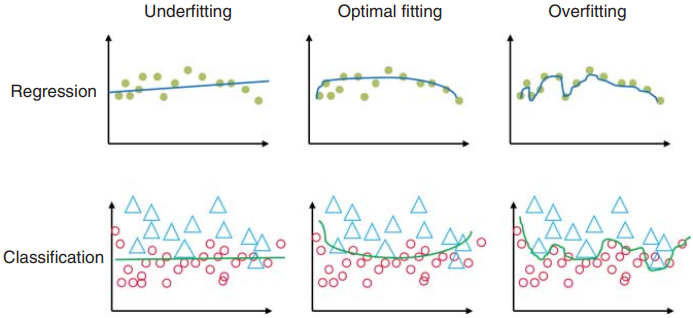
图1.19 模型欠拟合和过拟合的图示。
4. 维度的诅咒:机器学习的另一个关键方面是维度的诅咒。维度的诅咒与过拟合密切相关。在高维空间中,大多数训练数据都位于定义特征空间的超立方体的角落。特征空间角落中的实例比超活跃球体质心周围的实例更难分类。因此,随着特征或维度数量的增加,我们需要准确泛化的数据量也呈指数级增长。
1.7.2 优化器
优化器是帮助改变模型的权重和偏差的方法,以便将损失函数最小化。对标准随机梯度下降 (SGD) 算法提出了一些修改,即![]() ,其中)
,其中)![]() 、
、![]() 分别表示损失函数及其导数。
分别表示损失函数及其导数。![]() 和
和![]() 表示更新步骤后和之前的权重,λ表示学习率。以下是改进标准 SGD 的优化器列表:
表示更新步骤后和之前的权重,λ表示学习率。以下是改进标准 SGD 的优化器列表:
1. 动量:它加速SGD朝向相关方向,同时减少振荡。它基本上是将先前权重更新的一部分添加到当前更新向量中,从而确保在一定程度上保留先前更新的方向,同时使用当前更新梯度来微调最终更新方向。动量引入了另一个变量![]() ,可以表示如下
,可以表示如下
 (1.63)
(1.63)
2. Nesterov 加速梯度 [45]:虽然动量有助于降低噪声并加速收敛,但它也会引入误差。在Nesterov加速梯度中,通过将先前的权重更新的一部分包含在当前更新向量中以执行权重更新来解决此问题,其表示如下:
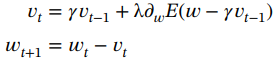 (1.64)
(1.64)
γ的典型值 = 0.9。
3. Adagrad [46]:Adagrad 的动机是每个参数都有一个自适应学习率;然而,早期的方法具有固定的学习率。Adagrad 确保依赖于迭代的隐藏层的不同神经元具有不同的学习率。其背后的直觉是,对于不频繁的参数,应该进行较大的更新,而对于频繁的参数,应该进行较小的更新。对于每次权重更新,学习率调整如下:
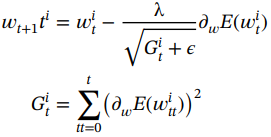 (1.65)
(1.65)
由于梯度的平方和不断增长,因此自适应地会导致较小的学习率。参数ε有助于避免除以零的问题。
4. RMSprop [47]:Adagrad 的一个问题是,在DNN中经过几次迭代后,学习速率变得非常小,从而导致死神经元问题,并导致这些神经元没有更新。RMSprop 修复了此问题,即使在多次参数更新后,学习也可以继续。在RMSprop 中,学习率是梯度的指数平均值,而不是像 Adagrad 中那样的梯度平方和的累积和。通过将梯度累积限制在某个过去来计算每个权重的平方梯度的移动平均值,可以表示如下:
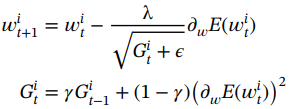 (1.66)
(1.66)
5. Adadelta [48]:Adadelta 是对 Adagrad 的另一项改进,可在多次参数更新后继续学习。但 Adadelta 的计算成本很高。在这里,梯度累积仅限于某个过去的更新,方法是计算每个权重参数的平方梯度和参数更新的移动平均值,如下所示:
 (1.67)
(1.67)
6. 自适应矩估计(ADAM)[49]:Adam 优化器是当今最流行和使用最广泛的优化器之一。它既存储类似于动量的过去梯度的衰减平均值,也存储过去平方梯度的衰减平均值,类似于 RMSprop和Adadelta。ADAM可以表示为以下等式,其中动量通过使用第一和第二矩添加到RMSprop中,即梯度的平均值![]() 和方差
和方差![]() :
:
 (1.68)
(1.68)
其中β1和β2是梯度均值和方差的移动平均实现中的遗忘因子。Adam易于实现且计算效率高,并且由于移动平均实现,需要的内存更少。
1.7.3 损失函数
神经网络被表述为一个优化问题。候选解,即网络的权重,应最小化或最大化给定目标函数的分数。
在回归问题的情况下,目标是预测一个实值量。在这种情况下,在输出层使用线性激活单元,并使用 MSE 作为损失函数。回归的均方损失如下:
![]() (1.69)
(1.69)
其中y和ŷ分别是神经网络的真实值和预测值。
对于分类问题建模,其思路是将输入变量映射到类标签,这意味着目标是预测示例属于特定类的概率。在最大似然估计下,网络的训练试图找到一组模型权重,以最小化模型给定数据集的预测概率分布与训练数据集中概率分布之间的差异。这称为CE损失,在二元分类的情况下,在输出端配置为sigmoid激活,而对于多类分类,在输出端使用 softmax 激活。在这两种情况下,问题都表述为预测属于特定类的给定输入的最大可能性。
二元分类的二元CE损失如下:
![]() (1.70)
(1.70)
其中p是类1的概率,1−p 是类0的概率,ŷ是神经网络的预测概率。